 One little article I wrote 15 years ago for Salon has been making the rounds again recently (probably because Andrew Leonard recently linked to it — thanks, Andrew!).
One little article I wrote 15 years ago for Salon has been making the rounds again recently (probably because Andrew Leonard recently linked to it — thanks, Andrew!).
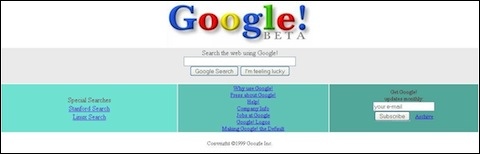
This piece was notable because it introduced Salon’s readers to a new service with the unlikely name of Google. My enthusiastic endorsement was based entirely on my own happy experience as a user of of the new search engine, and my great relief at finding a new Web tool that wasn’t larded up with a zillion spammy ad-driven come-ons, as so much of the dotcom-bubble-driven Web was at the time. The column was one of the earlier media hits for Google — it might’ve been the first mention outside the trade press, if this early Google “Press Mentions” page is complete.
Today I see a couple of important stories buried in this little ’90s time capsule. One is about money, the other about innovation.
First, the money: A commenter over at Hacker News expressed the kind but deluded wish that I had somehow invested in Google at that early stage. Even if I had been interested (and as a tech journalist, I wasn’t going to go down that road), the company had only recently incorporated and taken on its first private investment. You couldn’t just walk in off the street and buy the place. (Though that didn’t stop Salon’s CEO at the time from trying.)
In its earliest incarnation, and for several years thereafter, the big question businesspeople asked about Google was, “How will they ever make money?” But the service that was so ridiculously appealing at the start thanks to its minimalist, ad-free start page became the Gargantua of the Web advertising ecosystem. Despite its “Don’t be evil” mantra and its demonstrable dedication to good user experience, Google also became the chief driver of the Web’s pay-per-click corruption.
I love Google in many ways, and there’s little question that it remains the most user-friendly and interoperability-minded of the big Web firms. But over the years I’ve become increasingly convinced that, as Rich Skrenta wrote a long time ago, “PageRank Wrecked the Web.” Giving links a dollar value made them a commodity.
Maybe you’ve noticed that this keeps happening. Today, Facebook is making relationships a commodity. Twitter is doing the same to casual communication. For those of us who got excited about the Web in the early ’90s because — as some smart people once observed — nobody owned it, everyone could use it, and anyone could improve it, this is a tear-your-hair-out scenario.
Or would be, except: there’s an escape route. Ironically, it’s the same one that Larry Page and Sergei Brin mapped out for us all in 1998. Which brings us to the second story my 1998 column tells, the interesting one, the one about innovation.
To understand this one, you have to recall the Web scene that Google was born into. In 1998, search was over. It was a “solved problem”! Altavista, Excite, Infoseek, Lycos, and the rest — all these sites provided an essential but fully understood service to Web users. All that was left was for the “portal” companies to build profitable businesses around them, and the Web would be complete.
Google burst onto this scene and said, “No, you don’t understand, there’s room to improve here.” That was correct. And it’s a universal insight that never stops being applicable: there’s an endless amount of room to improve, everywhere. There are no solved problems; as people’s needs change and their expectations evolve, problems keep unsolving themselves.
This is the context in which all the best work in the technology universe gets done. If you’re looking for opportunities to make a buck, you may well avoid markets where established players rule or entrenched systems dominate. But if you’re looking for better ways to think and live, if you’re inspired by ideals more than profits, there’s no such thing as a closed market.
This, I think, is the lesson that Doug Engelbart, RIP, kept trying to teach us: When it comes to “augmenting human intellect,” there’s no such thing as a stable final state. Opportunity is infinite. Every field is perpetually green.