
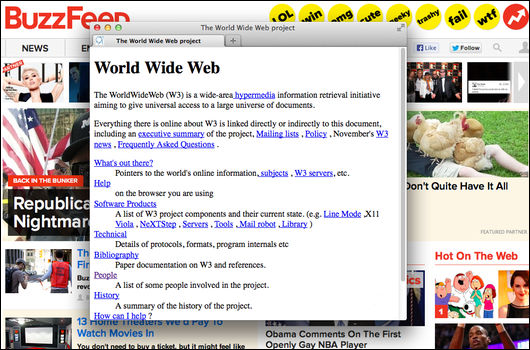
“The WorldWideWeb (W3) is a wide-area hypermedia information retrieval initiative aiming to give universal access to a large universe of documents.”
That’s how the Web first defined itself to the world.
Today is apparently the 20th anniversary of the moment when Tim Berners-Lee and his colleagues at CERN, the advanced physics lab in Geneva, made the Web’s underlying code free and public. CERN has a big project up to document and celebrate. As part of that project, it has posted a reproduction of the home page of the first public website.
The definition above is the first sentence on that page. Let’s unpack it!
The WorldWideWeb
I’m guessing this odd treatment — one word with CamelCase capitalization — was an inheritance from the Unix programming world in which Tim Berners-Lee worked and the Web hatched. It’s been years since anyone wrote it this way (even the W3C adds spaces). Spaces don’t work in old-school file names and the Web was conceived as a direct way to interconnect the file systems on networked servers, so leaving out the spaces made sense. Today it’s a style-book fight just to keep people from lower-casing “the Web.”
wide-area
The Web was all about moving our conception of a network from the thing that let one computer talk to another (or a printer) in an office to the thing that connected people and data around the world. In those days networks were considered “LANs” — local-area networks — or “WANs” — wide-area networks. LANs were in physically proximate spaces like large offices or, later, homes. WANs were bigger — computers connected first by phone lines and later by an alphabet-soup of higher-speed connections like ISDN, DSL, T1, and so forth. But it wasn’t clear what one would do with a WAN until the Web came along and showed us.
hypermedia
The term that emerged from Ted Nelson’s work on hypertext, popularized by Apple’s HyperCard, meaning texts and documents that are connected by crosslinks. The Web made links second nature for many of us, but we still haven’t fully digested all their possibilities — or stopped arguing about their pros and cons.
information retrieval
It’s fascinating to recall just how simple the Web’s bones are. Its underlying protocols provide a simple collection of action verbs — “get,” “post” and “put” — that describe sending and receiving information. That’s it. All the other stuff we do online today is built on that foundation.
initiative
The Web was not a startup. It was a collaborative “initiative.” This caused many in the tech industry to dismiss it; how could it ever compete against the mighty, money-driven behemoths like Compuserve, Prodigy and AOL, or, later, MSN?
universal access
The Web would be “free” and “open,” as the CERN page now says. No tollgates or licensing fees or dues or rent. Of course there was money in the system; the rapid commercialization of the Internet on which the Web still rests still lay in the future in 1993, but it was already in sight. But the piece of the system that made the Web the Web was going to be free of charge and free to tinker with.
With the right networking technology, it’s easy to make something universally available; it’s much harder to create something that the universe actually wants. That was the genius of the Web.
large universe of documents
This is the phrase that still excites and haunts me. The Web was originally about “documents,” not functional code. It was a publishing platform for the sharing of what we now refer to as “static files.” The phrase reminds us of the irresistible invitation the Web made to non-programmers: you too can contribute! You don’t need to code! HTML is a “markup language” and can be learned in minutes! (That was true, then.)
Today’s Web is infinitely more capable, and more complex. Over the past decade, modern browsers and javascript have turned it into an adaptable programming environment that first rendered the old MSOffice-driven desktop world obsolete and now faces its own challenges in the mobile world.
That’s great! It’s where I live and work now. But there will always be a corner of my mind and heart set aside for the Web as that simpler enterprise — that thing that just lets anyone explore and expand a “large universe of documents.”
Post Revisions:
- April 30, 2013 @ 10:17:55 [Current Revision] by Scott Rosenberg
- April 30, 2013 @ 10:15:44 by Scott Rosenberg